Page Slot Management
Because scrapers rely on web browsers, and one browser page can only handle one country at a time, we need a way to dynamically open and close browser pages to best match the number of scraping tasks per country, while not exceeding server resources.
This application solves this problem by introducing the concept of "page slot": a sort of placeholder for browser page. A page slot is linked to one country, and can have zero or one opened browser page. A server can host multiple page slots, for example a 16 CPU machine can host about 20 page slots. Each page slot is an independent OS process controlled by the application.
Page slots are managed via two scheduled jobs:
PageSlotAllocationJob: allocate page slots to best match the number of scraping tasks per country.PageSlotPreparationJob: start page slots according to the pending scraping tasks.
The following diagram illustrates how these two jobs work:
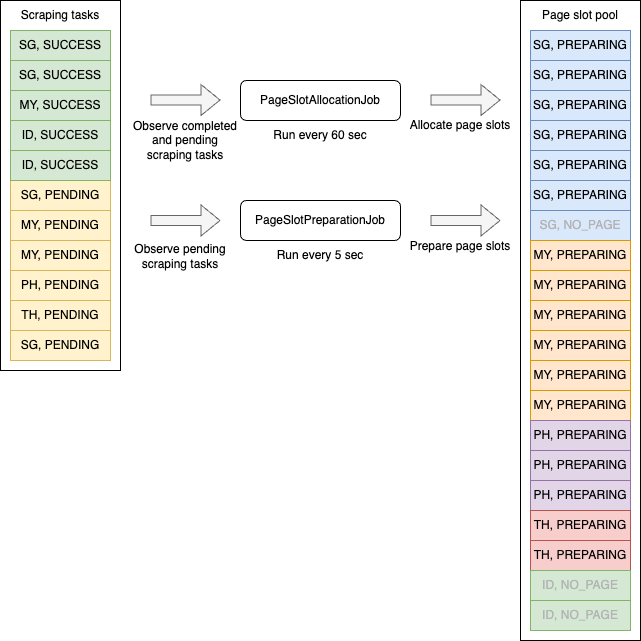
PageSlotAllocationJob
The PageSlotAllocationJob run every 60 seconds, it counts the number of scraping tasks per country, and assign a
score for each country:
const scoreByCountry = new Map([
['SG', 0], ['MY', 0], ['PH', 0], ['TH', 0], ['VN', 0], ['ID', 0]
]);
for (const scrapingTask of scrapingTasks) {
const cumulatedScore = scoreByCountry.get(scrapingTask.country);
const taskScore = scrapingTask.isCompleted() ? 10 : 30; // Higher score on pending tasks
scoreByCountry.set(scrapingTask.country, cumulatedScore + taskScore);
}
The total number of analyzed scraping tasks is capped at 3000.
The PageSlotAllocationJob then tries to create and delete page slots to best match the calculated score:
const MAX_PAGE_SLOTS = 20; // From the configuration
const totalScore = [...scoreByCountry.values()].reduce((total, score) => total + score, 0);
const pageSlotCountByCountry = [...scoreByCountry].reduce((countByCountry, [country, score]) => {
countByCountry.set(country, Math.round(MAX_PAGE_SLOTS * score / totalScore));
return countByCountry;
}, new Map())
The real implementation is a bit more complex to make sure that we don't exceed the maximum number of page slots.
If a country has too few scraping tasks (compared to other countries) to get a page slot, a page slot may still be allocated for this country if these scraping tasks are waiting for more than 50 seconds.
In the example of the diagram above, 7 pages slots are allocated for SG, 6 for MY, 3 for PH, 2 for TH and 2 for ID.
PageSlotPreparationJob
After page slots are allocated, they are in the NO_PAGE status and no web browser is running for them.
The role of the PageSlotPreparationJob is to start a browser and open a page to run pending scraping tasks. It works
like this:
- Count the number of page slots by country
- Count the number of pending and running scraping tasks per country (ignore countries with no page slot)
- For each country, calculate the number of page slots to start with the following algorithm:
const MIN_SCRAPING_TASKS_BY_PAGESLOT = 1/3; // From the configuration
const startedPageSlotCountByCountry = new Map();
for (const countryStat of countryStats) {
const startedPageSlotCount = Math.min(countryStat.pageSlotCount, Math.ceil(countryStat.scrapingTaskCount / MIN_SCRAPING_TASKS_BY_PAGESLOT));
startedPageSlotCountByCountry.set(countryStat.country, startedPageSlotCount);
}tipAs you can see,
MIN_SCRAPING_TASKS_BY_PAGESLOTdetermines how many page slots are started per scraping task:- if it is greater than 1 (e.g. 4) then less page slots are started per scraping task (e.g. 1 page slot for 4 tasks), which saves proxy traffic money but increase the time to complete the tasks in case of blockages.
- if it is a fraction of 1 (e.g. 1/3) then more page slots are started per scraping tasks (e.g. 3 page slots for one task), which decrease the time to complete the task (as we open multiple browser pages in parallel), but increase proxy traffic cost.
- The job then starts the page slots that are in the
NO_PAGEstatus.
In the example of the diagram above, MIN_SCRAPING_TASKS_BY_PAGESLOT is set to 1/3, so up to 3 page slots are started
per scraping task, resulting in 6 page slots for SG, 6 for MY, 3 for PH and 2 for TH (since there is only 2 allocated page slots).
IdleBrowserClosingJob
An additional job, not illustrated in the diagram above, automatically close page slot browsers after an inactivity of 60 seconds.
Page slot state machine
The following diagram illustrates the page slot state machine:
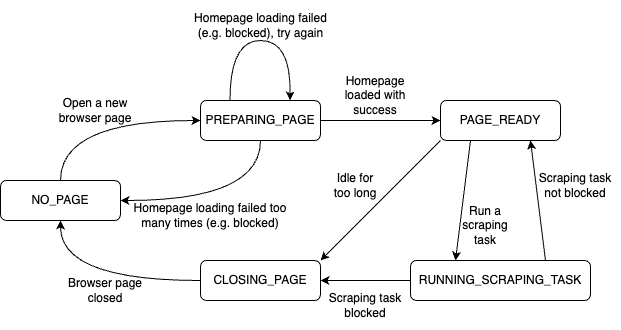
The PageSlotPreparationJob changes page slot state from NO_PAGE to PREPARING_PAGE, where it tries to load
the target website. If it succeeds, the status changes to PAGE_READY. If it fails, the page is re-opened and the
target website is loaded again.
To save proxy traffic, images, fonts and other non-essential assets are blocked, reducing website loading to a few KB in total.
After 4 consecutive failures to open the website, the web browser is closed and reopened. After 7
consecutive failures, the web browser is closed and the page slot status is changed back to NO_PAGE.
Hopefully, with good proxy, the page slot should stay in the PAGE_READY and RUNNING_SCRAPING_TASK statuses as long as possible.
When a scraping task has been blocked, or if the page slot has been idle for 60 seconds, its status is changed
to CLOSING_PAGE, its web browser is closed, and finally the status is changed to NO_PAGE.